Schema and Data Model
Transforming a dataset's structure requires using FME to manipulate schemas. FME uses the term "schema," but you may know this as the data model.
Schema Concepts
A schema defines the structure of a dataset. Each dataset has its unique schema; it includes layers, attributes, and other rules that define or restrict its content.
For example, the schema of an Excel workbook of (simplified) business data for a local bank chain might look like this:
| Worksheet | Column | Type |
|---|---|---|
| Customers | Name | String |
| Customers | Address | String |
| Customers | Phone | String |
| Customers | Account Number | Integer |
| Customers | Branch ID | Integer |
| Locations | Branch Name | String |
| Locations | Branch ID | Integer |
| Locations | Address | String |
| Locations | Phone | String |
| Locations | Sales | Integer |
FME lets you preserve the schema of your data while converting it to a new format, optionally letting you change the schema to alter the structure of your data. For example, you could remove the Locations worksheet from the output data, or make a new attribute that classified bank branches by their sales bracket.
Schema Representation
When you create a new workspace, FME scans the source datasets. It creates a reader whose feature types appear on the left side of the workspace canvas and a writer whose feature types appear on the right side of the workspace canvas:

| TIP |
| Each object in this illustration represents a subdivision in the source dataset. Remember, in FME terminology these objects are called feature types. Multiple feature types mean there are multiple layers or tables in the source dataset. |
Reader Schema
For the reader, you can view more information about the schema by clicking the cog-wheel icon on each feature type object:
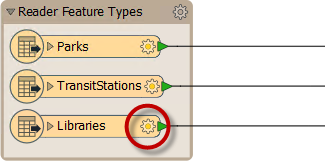
This Feature Type dialog has several tabs. Under the Parameters tab is a set of general parameters, such as the name of the feature type (in this case Libraries) the allowed geometry types, and the name of the parent dataset:
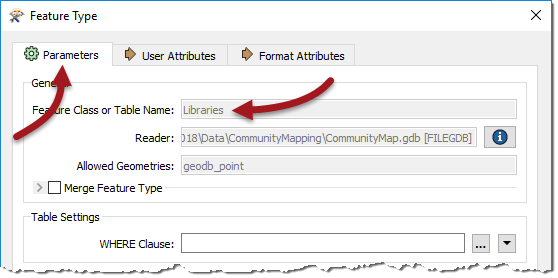
The User Attributes tab shows a list of attributes. Each attribute has information about its name, data type, width, and number of decimal places:
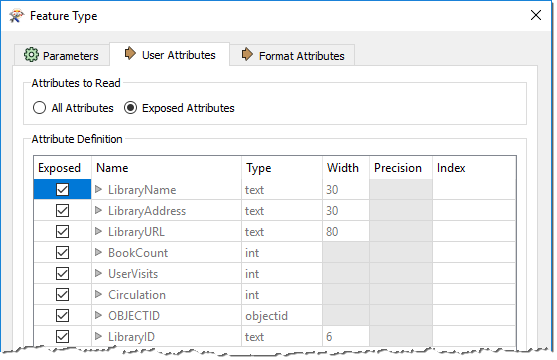
Each feature type has a different name and can also have a completely different set of attributes. All of this information goes to make up the reader schema. It is literally "what we have."
Writer Schema
As with the reader, each writer has a set of detailed schema information accessed by opening the dialog for a feature type:
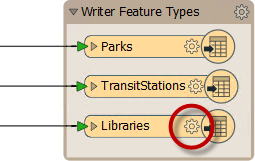
By default, the writer schema ("what we want") is a mirror image of the source, so the output from the translation will be a duplicate of the input. This feature allows users to translate from format to format without further edits (Quick Translation).
Schema Editing
If "what we want" is different to the default schema definition, we have to change it using a technique called schema editing. This process involves altering the writer schema to customize the structure of the output data. One good example is renaming an attribute field.
After editing, the source schema still represents "what we have," but the destination schema now truly does represent "what we want."
Schema Mapping
When using Generate Workspace, the reader and writer schemas will be identical. However, when edits occur, these connections are usually broken.
Schema mapping is the process of connecting the reader schema to the writer schema in a way that ensures the correct reader features go to the correct writer feature types and the correct reader attributes go to the correct writer attributes.
FME permits mapping from source to destination in any arrangement desired. There are no restrictions on what feature types or attributes may be mapped.