Inspecting Output
Inspecting the output of a translation is simply a case of viewing it in either the FME Data Inspector or the application in which the data is intended to be used.
It should be straightforward to check a dataset and see if any of its components are incorrect. However, it is important not to jump to conclusions about where a problem occurred.
Generally, issues in an output dataset can occur at one of three operations:
- The data was incorrectly transformed in FME Workbench
- The data was incorrectly written by FME Workbench
- The data is being incorrectly interpreted by another application
For example. You open an FME-generated dataset in application X and find that "Parc national des Pyrénées" is rendered as "Parc national des Pyr�n�es". Obviously an encoding problem has occurred, but where?
Maybe the data was incorrectly encoded before FME read it? Or maybe the data was correct but FME wrote it using the wrong encoding? Or maybe FME wrote the data correctly, but application X does not support that form of encoding?
So, the fact that data appears incorrect in another application is no real indication of where that problem was introduced. In this scenario it's best to check the data in the following order:
Inspect the "Pre-Output" Data
Because FME has the option Redirect to FME Data Inspector (and the option to Run with Full Inspection) it's possible to look at the data before it is written to the output dataset.
So, if a problem occurs in the output, first re-run the translation with one of these options and check whether the data is correct before FME tried to write it.
In the above example, if the Data Inspector shows � characters at this point:
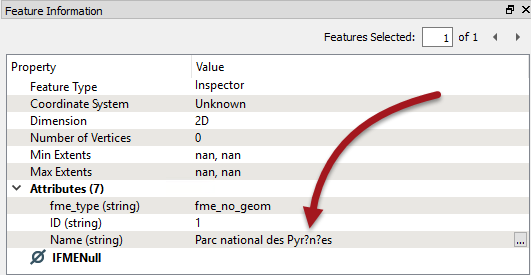
...then the data was bad before FME even tried to write it. Go back to the source data and check if that is even correct, before checking the workspace to see if encoding might have been affected in there.
| TIP |
| Be aware that "Run with Full Inspection" will take up more time and system resources, and also needs all Writers disabled separately to avoid still writing data. |
Inspect the Output Dataset in FME
If the "pre-output" data is correct then any issue is not in the data transformation; therefore it might be that it is being written incorrectly.
So, open the output dataset in the FME Data Inspector. This will show the data as FME wrote and interpreted it. If the data is incorrect here then the problem likely occurred during writing of the data.
In the above example, if the Data Inspector shows � characters at this point, then the data has been mangled when it was being written. Either FME has a limitation in that writer or the workspace author has set an encoding parameter incorrectly on the writer.
| TIP |
Another technique - for non-binary formats - is to open the dataset in a text editor for inspection. This can give you absolutely definitive proof of what has been written to the output file, without the possibility of it being re-interpreted by a different software application.
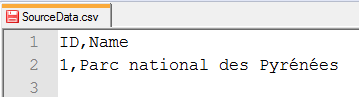
This proves this dataset contains the correct encoding (and is being viewed on a computer that supports it). Of course you would want to check whether your text editor (and computer) could view accented characters before assuming that � was a problem in the data and not the text editor! |
Inspect the Output Dataset in Another Application
If the "pre-output" data was correct, and the dataset still looked correct in the FME Data Inspector, then it might be that the intended application is not viewing the data correctly.
So, open the output dataset in the application in which it is intended to be used. If the data is only incorrect here then the problem is more likely to be with how the application interprets the data.
In the above example, if the data was correct within FME, and it written correctly by FME (especially when a text editor proves it) then suspicion falls upon the application that is showing � characters:
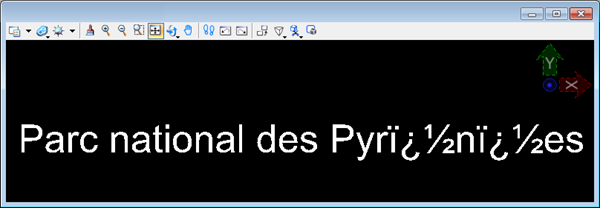
That would be particularly true if the format was non-native to that application (for example, reading a Geodatabase outside of an Esri product).
| Sister Intuitive says... |
|
All of the above techniques are for narrowing down where an error might have occurred, but it doesn't rule out any other cause.
For example, a dataset looks correct on application X, but crashes application Y. Does that mean application Y has a problem? On one hand yes (it shouldn't crash) but maybe application X is just more tolerant of bad data? In short, these techniques identify where to investigate first, but won't provide an absolute answer by themselves. |