| Exercise 1 | Noise Control Laws Project (Addresses) |
| Data | Addresses (File Geodatabase) |
| Overall Goal | Convert a File Geodatabase to Microsoft Excel and map the schema |
| Demonstrates | Attribute Management for Schema Mapping |
| Start Workspace | None |
| End Workspace | C:\FMEData2017\Workspaces\DesktopBasic\Transformers-Ex1-Complete.fmw |
City councillors have voted to amend noise control laws and local residents living in affected areas must be informed of these changes.
You have been recommended by your manager to take on the task of finding all affected addresses. There's a tight deadline and at least three city councillors are standing watching you work. The pressure is on and it's up to you to deliver!
This exercise is the first part of the project. You know that the address database for the city is stored in an Esri Geodatabase whose schema matches the Local Government Information Model PostalAddress table.
However, you are told that the software used to carry out automated bulk mailings requires addresses stored in an Excel spreadsheet using a completely different schema.
So, your first task is to create a workspace that converts addresses from Geodatabase to Excel, mapping the schema at the same time.
1) Inspect Data
As usual, the first task is to familiarize yourself with the data. To do this open the following dataset within the FME Data Inspector:
| Reader Format | Esri Geodatabase (File Geodb API) |
| Reader Dataset | C:\FMEData2017\Data\Addresses\Addresses.gdb |
| .1 UPDATE |
| In FME2017.1 the format is now called Esri Geodatabase (File Geodb Open API) |
The table that is to be translated is called "PostalAddress." The important thing here is not how the data looks in the graphic display, but more what attributes exist in the Table View window.

Optionally you may wish to locate the file C:\FMEData2017\Resources\DesktopBasic\AddressSchema.xsd and open it in a text editor (or other XML file viewer). An xsd file describes the schema of an XML/GML dataset, and this file has been created to define what attributes we wish to have in our address Excel dataset.
| TIP |
| To be clear, in this exercise we're going to write to an Excel dataset, setting it up by importing attribute definitions stored in an XML schema document. |
2) Create Workspace
Now that you are familiar with both the source data and the required output schema, start FME Workbench and begin with an empty workspace. Select Readers > Add Reader from the menubar.
Add the Reader with the same values as in the Data Inspector.
| Reader Format | Esri Geodatabase (File Geodb API) |
| Reader Dataset | C:\FMEData2017\Data\Addresses\Addresses.gdb |
When prompted, select only the PostalAddresses table, and no others:

| .1 UPDATE |
In FME2017.1 the dialog now has some additional icons:
|
3) Add Writer
Now let's add a Writer to write the output data. Select Writers > Add Writer from the menubar and use the following:
| Writer Format | Microsoft Excel |
| Writer Dataset | C:\FMEData2017\Output\Training\AddressFile.xlsx |
Select 'Import from Dataset' in the 'Add Feature Types' section of the dialog:
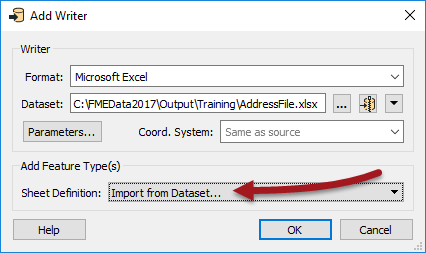
Then Click OK to add the Writer.
4) Import Feature Types
At this point you are prompted to select the dataset to import a schema definition from. The Dataset can be left as it is or emptied (left blank). It is not the important part:
| Reader Format | GML (Geography Markup Language) |
| Reader Dataset | |
| Reader Parameters | Application Schema C:\FMEData2017\Resources\DesktopBasic\AddressSchema.xsd |
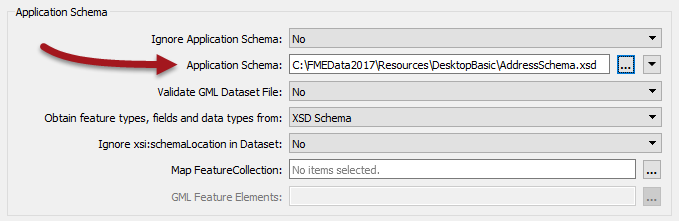
Click OK to accept the values. The new feature type will be created to match the chosen GML application schema.
The workspace will now look like this:

There are three GML attributes imported by default. These aren't needed, so to clean up the schema open the feature type User Attributes tab and delete them.
While you are in the same dialog, also change the data type of the UpdateDate field from string to datetime.
5) Add AttributeManager
OK, we now have the reader and writer in place. Now we can start to map the schema from reader to writer. As you'll have noticed, the two do not currently match up very well.
So, place an AttributeManager connected between the two feature types. Its parameters will look like this:
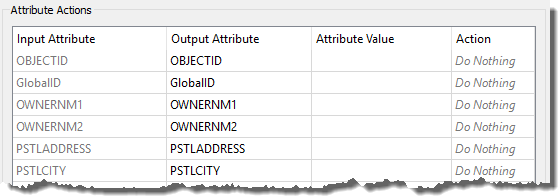
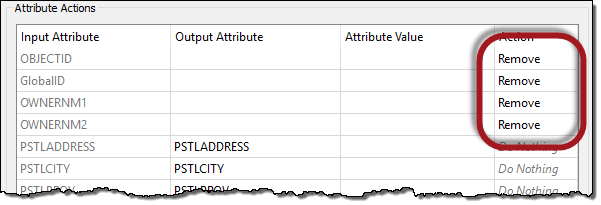
Firstly let's clear up the Reader schema by removing some of the unwanted attributes.
Click on the following attributes and press the - button to remove them:
- OBJECTID
- GlobalID
- OWNERNM1
- OWNERNM2
- INTSTATE
- INTPSTLCD
- REPRESENT
- STATUS
- LASTUPDATE
- LASTEDITOR
6) Rename Attributes
Several source attributes can be written to the output as they are, but do need renaming first.
In the AttributeManager rename the following:
- PSTLCITY to City
- PSTLPROV to Province
- POSTALCODE to PostalCode
- COUNTRY to Country

If the AttributeManager is connected to the writer feature type then you should be able to select the Output Attribute field from a drop-down list instead of typing it in.
7) Create Attribute (Provider)
Two attributes on the output (Provider and UpdateDate) are new and cannot be copied from the source data. They must be created.
In the AttributeManager create the new attribute "Provider". Because the attribute exists on the output schema, you can again select it from the drop-down list.
Set a fixed value such as your own organization name, "Safe Software", or "City of Interopolis."
8) Create Attribute (UpdateDate)
Now create the new attribute "UpdateDate". Rather than hard-coding a value click on the drop-down arrow in the Attribute Value field and choose Open Text Editor.
In the text editor locate the FME Feature Function called Timestamp and double-click to place it in the editor. By default it creates a datetime in ISO syntax, which is fine for us, so simply click OK to accept this.
Click OK again to close the AttributeManager dialog.
| .1 UPDATE |
| In FME2017.1 the @Timestamp function has been deprecated in favour of the function @DateTimeNow, which you should use instead. |
| TIP |
| Why not run the translation now, with Redirect to FME Data Inspector turned on, to see what the result of our efforts so far is? |
9) Add AttributeSplitter
Looking at the output schema there are two fields for Number and Street (for example "3305" and "W 10th Av"). However, the source schema condenses that information into one field with <space> characters separating the fields ("3305 W 10th Av"). Therefore we'll have to split the source attribute up in order to match the Writer schema.
Insert an AttributeSplitter transformer. Insert it before the AttributeManager - then if there are any actions to carry out on the split attributes we can use the same AttributeManager transformer.
View the AttributeSplitter parameters. Set PSTLADDRESS as the attribute to split and enter a space character into the Delimiter parameter. Ensure that a list name is set in that particular parameter.
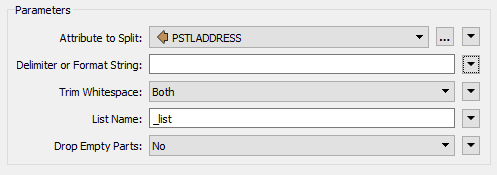
Click OK to close the dialog. If you run the workspace now you'll see the address as a list attribute:
_list{0} (encoded: utf-8) 3305
_list{1} (encoded: utf-8) W
_list{2} (encoded: utf-8) 10th
_list{3} (encoded: utf-8) Av
Remember a list attribute is one that can store multiple values under a single name (_list).
10) Rename Attribute
Now let's handle the Number field in the output. Go back to the AttributeManager parameters.
Notice that there is now an entry for the list attribute called _list{}. However, this is just the list attribute "in general" - it isn't showing each element (value) in the list.
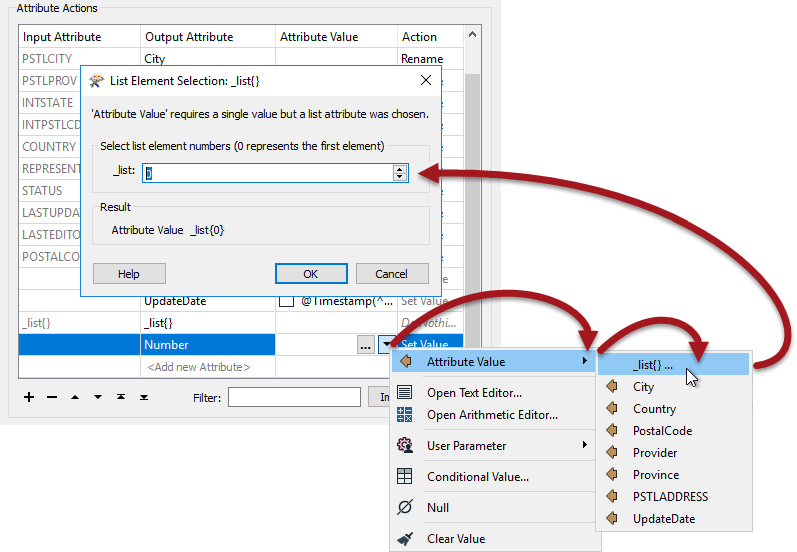
What we need to do is create a new attribute and copy the list element we want into it. So, in the Output Attribute field create a new attribute called Number by selecting it from the drop-down list.
For the Attribute Value field click the drop-down arrow and select Attribute Value > _list{}...
You will now be prompted to select the element in the list. Ensure it is set to zero (0) and click OK.
Click Apply/OK to confirm the changes and run the workspace to ensure the number is being copied.
| WARNING |
The Excel writer has a parameter called Overwrite Existing File, which by default is set to No.

This will be a problem if you are writing to the dataset rather than using the Redirect to Data Inspector setting, because each run will append data rather than overwriting. So this is probably a good time to change the parameter to Yes, just in case you need to run the workspace more than once! |
11) Construct Attribute
The final step is to recreate the Street attribute, without it being prefixed by the address number.
View the AttributeManager parameters again. This time in the Output Attribute field create a new attribute called Street by selecting it from the list.
Unlike the Number field, we want to create this value by concatenating several list elements. So click the drop down arrow in the Attribute Value field and choose Open Text Editor.
Locate _list{} in the FME Feature Attributes menu and carry out the following steps:
- Double-click _list{} and when prompted select element 1
- Press the spacebar to enter a <space> character
- Double-click _list{} and when prompted select element 2
- Press the spacebar to enter a <space> character
- Double-click _list{} and when prompted select element 3
The dialog will now look like this:

In this way we will have concatenated all parts of the street name back together, for example:
"W"+"17th"+"St" becomes "W 17th St"
We're assuming that no street name has more than three parts to it, but that's reasonable for our example.
12) Run Workspace
Save and then run the workspace (remember to turn off any Redirect option and ensure Overwrite Existing File is set to Yes!)
Open the containing folder to check the output has been written. Inspect the data in the FME Data Inspector. The output (in the Table View window) should look like this:

| TIP |
| The Event field is still empty at this point, but will be completed in a subsequent exercise. |
| CONGRATULATIONS |
By completing this exercise you have learned how to:
|