Adjacent Feature Attributes
Normally a feature in FME is self-contained. It might get processed as a group at some point, but other than that it doesn’t have any relationship to other features in the workspace.
However, in some cases, the ability for a feature to access the attributes of other features is quite useful.
For example, take a tabular dataset of coordinates recorded as follows:
| X | Y |
|---|---|
| +0.0 | +3.0 |
| +3.2 | +0.0 |
| -3.2 | +0.0 |
| +0.0 | +3.4 |
| +4.2 | +0.0 |
In this case each row is not an absolute coordinate; instead, it is an offset from the previous one. Therefore, to calculate the true coordinates, each feature needs to know the coordinates of the previous feature, so that it can apply the offset.
This sort of scenario is catered for by Adjacent Feature Attributes in FME.
Adjacent Feature Functionality
Adjacent Feature functionality is activated by checking the box labeled Enable Adjacent Feature Attributes in an AttributeCreator or AttributeManager transformer:
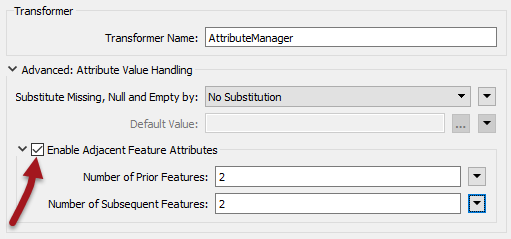
This opens up a section of dialog in which the author can specify how many features preceding the current feature, or how many features that succeed it, should be made available. In the above screenshot attributes from the previous and subsequent two features will become available.
Using Multiple Feature Attributes
The simplest way to make use of the attributes retrieved from prior/subsequent features is through the text or arithmetic editors, where the list of feature attributes has an expandable section for prior and subsequent features:
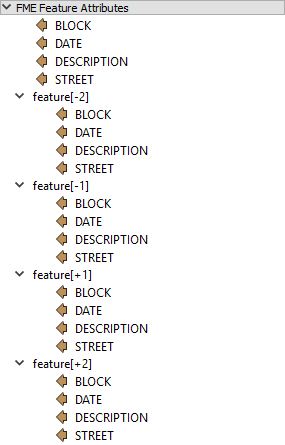
Notice above how attributes are available not only for the current feature but also for the previous/subsequent two features. As with the current attribute, double-clicking an adjacent attribute adds it to the expression window:
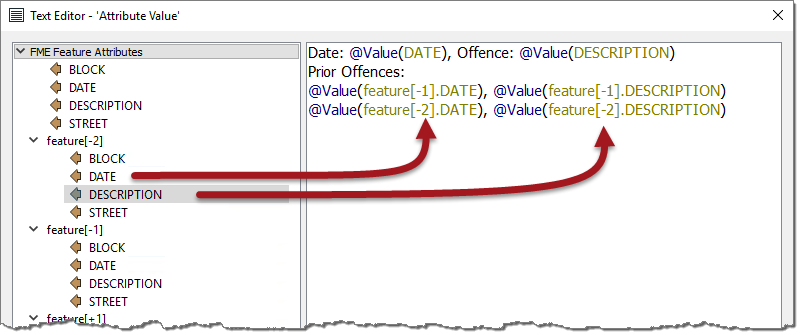
In the above screenshot, the workspace author is using data on parking offenses. They create a string composed of a date and an offense and then add the prior two offenses (we're assuming that the data is already sorted in date order).
You can see that prior and subsequent attribute values can be accessed simply by using feature[x].
| Professor Lynn Guistic says… |
|
This is a first-class piece of functionality, excellent to the highest degree.
However... be aware that extra system resources are used for storage of adjacent features. Therefore translation performance will take a (fairly minor) hit when using these capabilities, the degree of which depends on the number of attributes being retained. |
Missing Values
The AttributeCreator and AttributeManager also have an option to specify what should happen if the attributes being used in a string are missing:

When the transformer tries to use a value that is missing (or null or empty) this option lets the user choose a replacement value, or to carry out no substitution.
Notice that this setting applies to attributes of the current feature, just as much as attributes of adjacent features.
| Miss Vector says... |
|
My AttributeManager sets up NewAttribute = OldAttribute + feature[+1].OldAttribute
There are 100 features in my dataset. Given that feature[101].OldAttribute doesn't exist, what will the value of NewAttribute be for the 100th feature? 1. No value at all (empty attribute) 2. The same as feature[100].OldAttribute 3. It depends on the Substitute Value parameter 4. Nothing. FME will crash and explode your computer |