Database Optimization
FME can only be as fast as the database it is reading from or writing to. This section will help FME increase its efficiency when working with databases.
Database Reading
Reading and filtering data (querying) from a database is nearly always faster when you can use the native functionality of the database. Just as previously mentioned you can use the search envelope and WHERE clauses to narrow down what is being read from the database into FME.
Database Transformers
Besides readers, transformers can also be used to query database data. The best to use is the SQLExecutor (or SQLCreator) as these pass their queries to the database using native SQL. If you don’t want to write SQL then you can use the FeatureReader transformer, but be aware this transformer is more generic and won’t give quite the same performance.
The SQLExecutor is particularly worth being aware of, as it issues a query for each incoming feature. This can be useful where you need to make multiple queries.
For example, here a query is issued to the database for every library feature that enters the SQLExecutor:
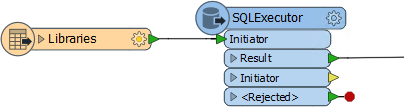
Generally, the output from the SQLExecutor is an entirely new feature. If you want to simply retrieve attributes to attach to the incoming feature, then the Joiner transformer is more appropriate.
Database Writing
Whereas the performance of reading from a database is largely dependent on the database setup itself, when writing to a database there are very many FME parameters that can help to fine-tune the overall performance.
Remember that writing to a database incurs network overheads. There has to be a balance between various components:
- The amount of data and number of requests being sent (network traffic)
- The amount of data stored by FME awaiting transfer to the database (FME performance)
- The amount of data stored in the database awaiting committal (database performance)
- The risk of losing uncommitted data
Each database writer has a set of parameters for handling these components. Not every format supports these, but the two most common parameters are Features per Transaction and Features per Bulk Write.
Features per Bulk Write
The Features per Bulk Write parameter tells FME how many features to send at a time to the database.
Features sent to an FME database writer get cached in memory until the number of features specified by this parameter is reached. Only then will they be sent to the database. This is also known as chunk size.
This parameter is a way to balance network traffic with FME performance. A higher number means FME caches more features (so uses more system resources), but makes fewer requests to the database (and therefore causes less network traffic).
A lower number means FME caches less data, but there are more requests made to the database.
Features per Bulk Write also needs to be considered against the value of Features per Transaction.
Features Per Transaction
Features per Transaction (also sometimes called Transaction Interval) controls how many features are entered into a database before a commit command is issued.
Features sent by an FME writer are cached in memory by the database until the number of features specified by this parameter is reached. Only then are they committed.
Each commit adds delay to the writing process, so setting this parameter must balance the speed of the translation (a higher number) against the risk that a translation may fail and features need to be rolled-back (a lower number).
For example, if this parameter is set to a value of 1, then each and every feature is committed individually. If the process fails then only the last feature will be lost from the database, but the cost is much-reduced performance.
Alternatively, if the parameter is set to a very high value (more than the number of features being written) then only one commit takes place and performance improves. However, if the translation fails, then all features previously written will be rolled-back and lost to the database.
If Features per Transaction is less or equal to Features per Bulk Write, then FME basically caches a number of features and sends them to the database where they are immediately committed.
If Features per Transaction is greater than Features per Bulk Write, then FME is sending features to the database where they will be cached until the transaction commit total is reached.
| Jake Speedie says… |
| The Transaction and Chunk parameters can differ from format to format. For example, SQL Server has a single Bulk Option flag rather than a numeric setting. Therefore it’s very important that you check out the FME Readers and Writers Manual to confirm what parameters are available for your database, and how exactly they operate. |
Writing and Indexing
Whereas indexes can improve performance for reading data, for writing they can cause a great reduction in the speed of translation.
That’s because the index will often get updated by the database automatically with every feature that is written to the database. This occurs on a per-feature basis, and regardless of commit intervals.
To remedy this it’s suggested that indexes are dropped (deleted) before carrying out bulk inserts of data into a database table.
A writer feature type also has options to truncate or drop tables when writing to them:
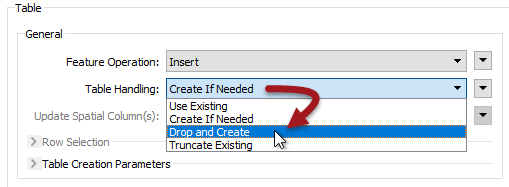
For the above reason, dropping a table is more efficient than truncating it because the drop action also removes the indexes.
For similar reasons, you may want to turn off networking connectivity when writing data to a Geodatabase geometric network.