| Exercise 4 | Garbage Collection Day Project |
| Data | Addresses (PostGIS or Esri Geodatabase) Garbage Zones (Esri Geodatabase) |
| Overall Goal | Analyze and improve the workspace performance |
| Demonstrates | Database Optimization |
| Start Workspace | C:\FMEData2018\Workspaces\DesktopAdvanced\WorkspaceDesign-Ex4-PostGIS-Begin.fmw C:\FMEData2018\Workspaces\DesktopAdvanced\WorkspaceDesign-Ex4-Geodatabase-Begin.fmw |
| End Workspace | C:\FMEData2018\Workspaces\DesktopAdvanced\WorkspaceDesign-Ex4-PostGIS-Complete.fmw C:\FMEData2018\Workspaces\DesktopAdvanced\WorkspaceDesign-Ex4-Geodatabase-Complete.fmw |
Members of the public often call the city to ask what day their garbage collection is. To help the city has an internal system hosted on FME Server. Members of the planning department can lookup an address ID, enter it into a published parameter, and the system retrieves the garbage pickup information.
The system works but is perhaps slower than it should be. Let’s run this short exercise to discover why.
| Miss Vector says... |
| This exercise uses either a PostGIS database hosted on Amazon RDS or an ESRI Geodatabase. You can use either one (no extra license is required). Be sure to open the correct workspace and follow the correct instructions for your chosen format. |
1) Create Database Connection (PostGIS Only)
To use a PostGIS database as source requires a connection to it.
In a web browser visit http://fme.ly/database - this shows the parameters for a PostGIS database running on Amazon RDS.
Start Workbench and select Tools > FME Options from the menubar
Click on the icon for the Database Connections category, then click the [+] button to create a new connection. In the "Add Database Connection" dialog enter the connection parameters obtained through the web browser.
Give the connection a name (if you call it FME Training Database Connection it will match the starting workspace) and click Save.
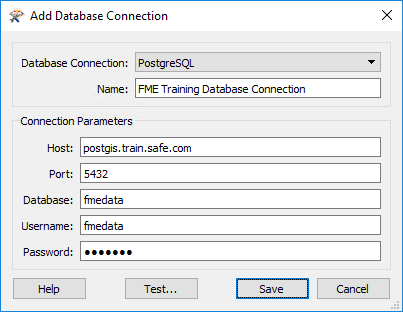
NB: Yes, the password is fmedata as well!
Then click OK to close the FME Options dialog.
2) Open and Run Workspace
Open the workspace C:\FMEData2018\Workspaces\DesktopAdvanced\WorkspaceDesign-Ex4-PostGIS-Begin.fmw or WorkspaceDesign-Ex4-Geodatabase-Begin.fmw.
The workspace looks something like this:
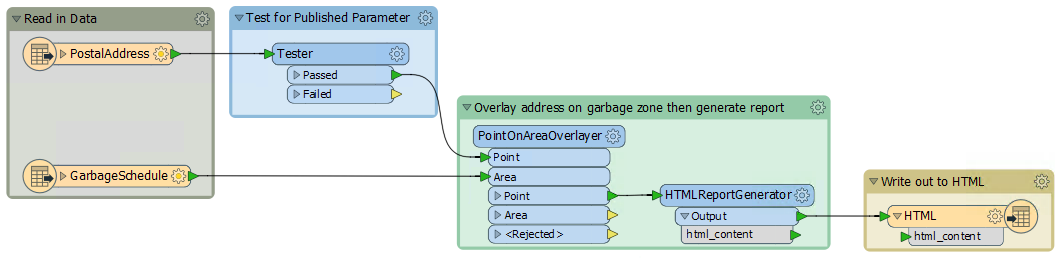
Basically, a published parameter accepts an address ID. The postal address database is read and filtered against this ID. The chosen address is used in a spatial overlay against garbage zones. The result is formatted in HTML and written out with a Text File writer.
To get a comparison, run the workspace. Use Prompt Mode to be prompted for an address ID. A suitable address ID to use is 127209 (PostGIS) or 6135 (Geodatabase).
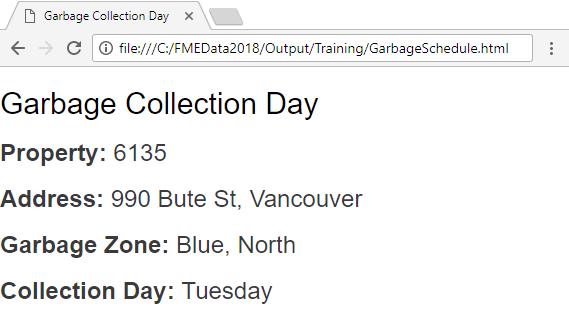
The result, in a web browser, is this:
The performance will read like this:
PostGIS
INFORM|FME Session Duration: 10.8 seconds. (CPU: 3.9s user, 0.5s system) INFORM|END - ProcessID: 7144, peak process memory usage: 123656 kB, current process memory usage: 123520 kB
Geodatabase
INFORM|FME Session Duration: 2.8 seconds. (CPU: 2.5s user, 0.3s system) INFORM|END - ProcessID: 8228, peak process memory usage: 133556 kB, current process memory usage: 117920 kB
The Geodatabase is quicker because it is being read from your own file system, not a remote database.
3) Set Up WHERE Clause
Neither PostGIS or Geodatabase have a WHERE clause for the reader itself, but their feature types do. So inspect the properties for the PostalAddress reader feature type and in the WHERE Clause parameter enter:
PostGIS
"AddressId" = $(AddressID)
Geodatabase
OBJECTID = $(AddressID)

For PostGIS, be sure to notice the lower-case "d" in the "Id" part of the field name! Also, note the difference in use of quotes between the two formats.
4) Delete Tester
Now we have the WHERE clause the Tester transformer is no longer required, so delete it.
| TIP |
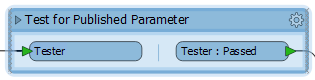
If you collapse the bookmark then delete the bookmark it deletes both the bookmark and the transformer in one step:
|
5) Re-Run Workspace
Re-run the workspace. This time only 1 feature is read from the database. The performance improves accordingly:
PostGIS
INFORM|FME Session Duration: 7.7 seconds. (CPU: 2.3s user, 0.3s system) INFORM|END - ProcessID: 1756, peak process memory usage: 122344 kB, current process memory usage: 122344 kB
Geodatabase
INFORM|FME Session Duration: 1.1 seconds. (CPU: 0.8s user, 0.3s system) INFORM|END - ProcessID: 7260, peak process memory usage: 124604 kB, current process memory usage: 117016 kB
Memory usage hasn’t improved, but the translation ran faster.
| CONGRATULATIONS |
By completing this exercise you have learned how to:
|