Parallel Processing
Parallel Processing is a way to improve performance on high-end machines.
What is Parallel Processing?
Each FME translation is usually a single process (fme.exe) on your computer. Parallel processing is when you transform your data into several simultaneous processes. The fact that they run simultaneously means the whole translation can run several times quicker than it used to.
Parallel processing allows FME to make use of multiple cores on a computer. There are four levels of parallel processing in FME, and each maps to the number of cores in this way:
| Parameter | Processes | Quad-Core Machine |
|---|---|---|
| No parallelism | 1 Process | 1 Process |
| Minimal | Cores / 2 | 2 Processes |
| Moderate | Cores | 4 Processes |
| Aggressive | Cores x 1.5 | 6 Processes |
| Extreme | Cores x 2 | 8 Processes |
So, as in the above example, on a quad-core machine, minimal parallelism results in two simultaneous FME processes. Extreme parallelism would result in eight (assuming there are eight tasks that can be processed simultaneously).
There is also a hard cap for each license level:
| FME Edition | Process Cap | Quad-Core Machine |
|---|---|---|
| Base Edition | 4 processes | Maximum 4 processes |
| Professional Edition | 8 processes | Maximum 8 processes |
| All Other Editions | 16 processes | Maximum 8 processes |
So, if you have a Base Edition license, you are never going to get more than four processes at one time, regardless of machine type and the parallelism parameter. The quad-core machine in the above example can never have more than eight processes since that is the maximum 'extreme' parallel processing allows.
| Jake Speedie says… |
| Parallel Processing is very effective when you are offloading a task elsewhere – for example calling a Server with the HTTPFetcher – as each process is a tiny impact on the FME system resources. However, be aware, each parallel process involves starting and stopping an FME engine, and this takes time. So, don’t parallelize your processes when the task already takes less than the time to stop/start FME! |
Transformers and Parallel Processing
A number of FME transformers have built-in options for parallel processing. Parallel processes work on groups of features, so the transformer must be group-based and have a group-by parameter for the user to define the parallel processing groups.
For example, this Bufferer transformer is set up to buffer a set of street features:
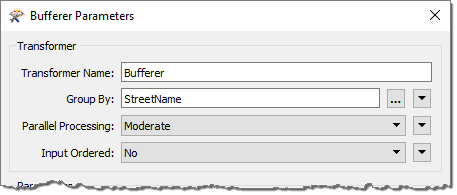
Each street (i.e., each feature with the same street name) is processed as a separate group. To speed up the translation, each group is handled as a separate process (sadly the user cannot confirm that the source data is already ordered by group, which could improve performance even more).
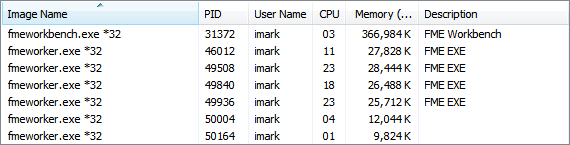
When a translation is run in parallel mode, then a number of “worker” processes appear in your process manager:
Parallel Processing Groups
Best performance gains occur with a small number of groups and a large amount of data. With many groups and only a few features, then performance gains will not be large and, in fact, the whole process might even be slower.
Because each group is processed independently, there can be no relationship between features in different groups. If features are related, and their results depend on each other, then they must be in the same group.
However, if all data is unrelated and the contents of the group are unimportant, then it’s possible to make artificial groups using a ModuloCounter or RandomNumberGenerator transformer.
For example, here the user has a large number of line features to buffer (separately) and uses a ModuloCounter to assign them to one of four groups for parallel processing. Note the Group By parameter in the Bufferer is set to the _modulo_count attribute:

| Jake Speedie says… |
| See this blog article for more information about - and some special techniques for - generating parallel processing groups. |