Dynamic Translations
Dynamic Translations are a way to create "schema-less" workspaces.
What are Dynamic Translations?
Most translations - and everything this training has covered so far - involve a schema defined within the workspace. In other words, the source and destination schema reflect the structure of the source data (what we have) and the structure of the destination data the user requires (what we want).
The layout of a dynamic translation does not reflect either the source or destination schema. It’s a universal layout that is designed to handle data regardless of the schema used.
| Sister Intuitive says… |
| For this section, it’s useful to think of a schema as comprised of a trinity of objects: feature types, attributes, and geometry type. |
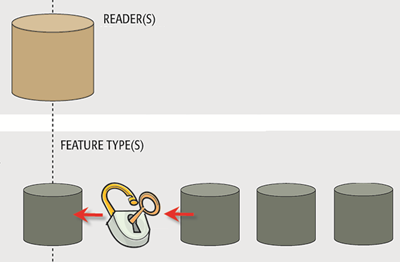
Dynamic Readers
On the reader side of things, a dynamic workspace is very similar to using Merge Parameters; feature types are given free entry to a workspace, regardless of whether they are yet defined in there.
Data is also read regardless of attributes or geometry type.
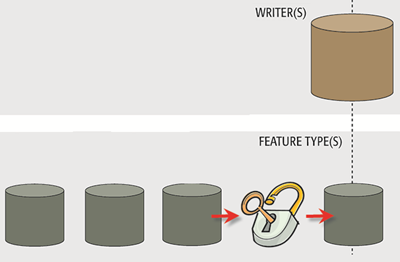
Dynamic Writers
The writer side of a dynamic workspace mimics the reader part; feature types are written to the destination dataset, regardless of whether they are defined in the workspace.
Additionally, all attributes and geometries get written, regardless of whether they too have been predefined in a writer feature type.
| Miss Vector says… |
|
It's important to get the concepts correct here, and I have some more statements only some of which are true:
1. A Dynamic workspace will read/write any format of data 2. A Dynamic workspace will read/write any feature types in the source data 3. A Dynamic workspace will read/write any attributes in the source data 4. A Dynamic workspace will read/write any geometry in the source data |